When Quantization Isn't Enough: Why 2:4 Sparsity Matters
Explores how combining 2:4 sparsity with 4-bit quantization consistently outperforms standalone 2-bit quantization for LLaMA models at equivalent compression ratios.TorchAO: PyTorch-Native Training-to-Serving Model Optimization
Presents TorchAO, a PyTorch-native framework covering quantization and sparsity from training to serving, with support for FP8, INT4, INT8, MXFP formats, and 2:4 sparsity, integrated across TorchTitan, TorchTune, vLLM, and more. ICML 2025 CODEML Workshop.Accelerating Transformer Inference and Training with 2:4 Activation Sparsity
Demonstrates how 2:4 sparsity applied to activations — exploiting intrinsic sparsity from Squared-ReLU — accelerates LLM inference and training with no accuracy loss, achieving up to 1.3x faster FFN operations. ICLR 2025 SLLM Workshop.Lightning Talk: Sparsifying Vision Transformers with Minimal Accuracy Loss
A lightning talk demonstrating techniques to sparsify Vision Transformers while preserving model accuracy.Accelerating Neural Network Training with Semi-Structured (2:4) Sparsity
A PyTorch blog post presenting a SemiSparseLinear layer that achieves 1.3x speedup in linear operations and 6% end-to-end wall time reduction on DINOv2 ViT-L training, with a custom pruning kernel 10x faster than cuSPARSELt.Speeding up ViTs using Block Sparsity
A PyTorch blog post demonstrating block sparsity on MLP module weights to accelerate Vision Transformers, achieving up to 1.46x speedup with less than 2% accuracy drop on A100 GPUs.(beta) Accelerating BERT with semi-structured (2:4) sparsity
A PyTorch tutorial covering the complete workflow for accelerating BERT for question-answering using semi-structured (2:4) sparsity — from magnitude pruning and fine-tuning to inference acceleration achieving ~1.3x speedup.Lecture 11: Sparsity
A lecture covering sparsity techniques in neural networks.Leveraging Neural Embeddings: Part V
This is the final part of a 5 part series about how I built a privacy focused but flexible NLP system at Cultivate, a startup building AI-tools to help managers.Leveraging Neural Embeddings: Part IV
This is part 4 of a 5 part series about how I built a privacy focused but flexible NLP system at Cultivate, a startup building AI-tools to help managers.Leveraging Neural Embeddings: Part III
This is part 3 of a 5 part series about how I built a privacy focused but flexible NLP system at Cultivate, a startup building AI-tools to help managers.Leveraging Neural Embeddings: Part II
This is part 2 of a five part series about how I built a privacy focused but flexible NLP system at Cultivate, a startup building AI-tools to help managers.Leveraging Neural Embeddings: Part I
This is a 5 part series about how I built a privacy focused but flexible NLP system at Cultivate, a startup building AI-tools to help managers.Startup Equity Primer
This is a analysis of SF AngelList job postings and a short explanation of early employee stock options.
I was researching job offers for startups in San Francisco, and wanted to get some real data.
Hopefully this can be a resource for anyone looking for work at startups in SF right now.
Learning Embeddings from Cooccurence Matrices
This post is about a couple of different ways to learn sentence representations, inspired by contrastive learning.
BERT fine-tuning and Contrastive Learning
So this summer I officially started doing research with UCLA-NLP.
My research this summer has been mainly focused on sentence embeddings. That is finding a function that maps a sentence (for our purpose a sequence of tokens) $S = [1, 10, 15, \ldots 5, 6 ]$ to a vector $v \in \mathbb{R}^d$.
Learning Better Sentence Representations
Over the past couple years, unsupervised representation learning has had huge success in NLP. In particular word embeddings such as word2vec and GloVe have proven to be able to capture both semantic and syntactic information about words better than previous approaches, and have enabled us to train large neural end-to-end networks that achieve the best performance on a myriad of NLP tasks.
This post is about contrastive unsupervised representation learning for sentences.
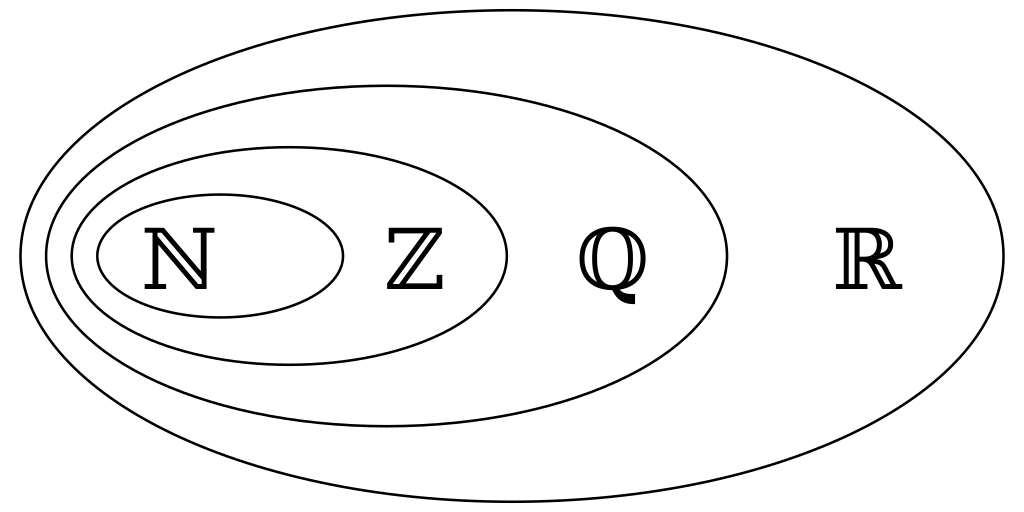
Building $\mathbb{Q}$ visually
I’m going to go over how to construct $\mathbb{Q}$, or the rational numbers.
We’re going to start by constructing the natural numbers, and from there we’ll construct the integers, and from the integers the rationals. Our goal here is to be able to perform arithmetic in the rationals - adding, multiplying, subtracting, and dividing numbers together in the way we expect.
Languages and Automata
Some notes for CS 181. This is about context-free grammars, pushdown automata, the pumping lemma for context-free grammars, and closure properties of context-free language. I also just added in notes for Turing machines.
Blend
I just finished working for a year at Blend, and now I’m back at UCLA as a student.
Working full-time was actually quite a bit different from what I expected. I wanted to talk a bit about the things I did, and what I liked/didn’t like about working full-time at Blend.
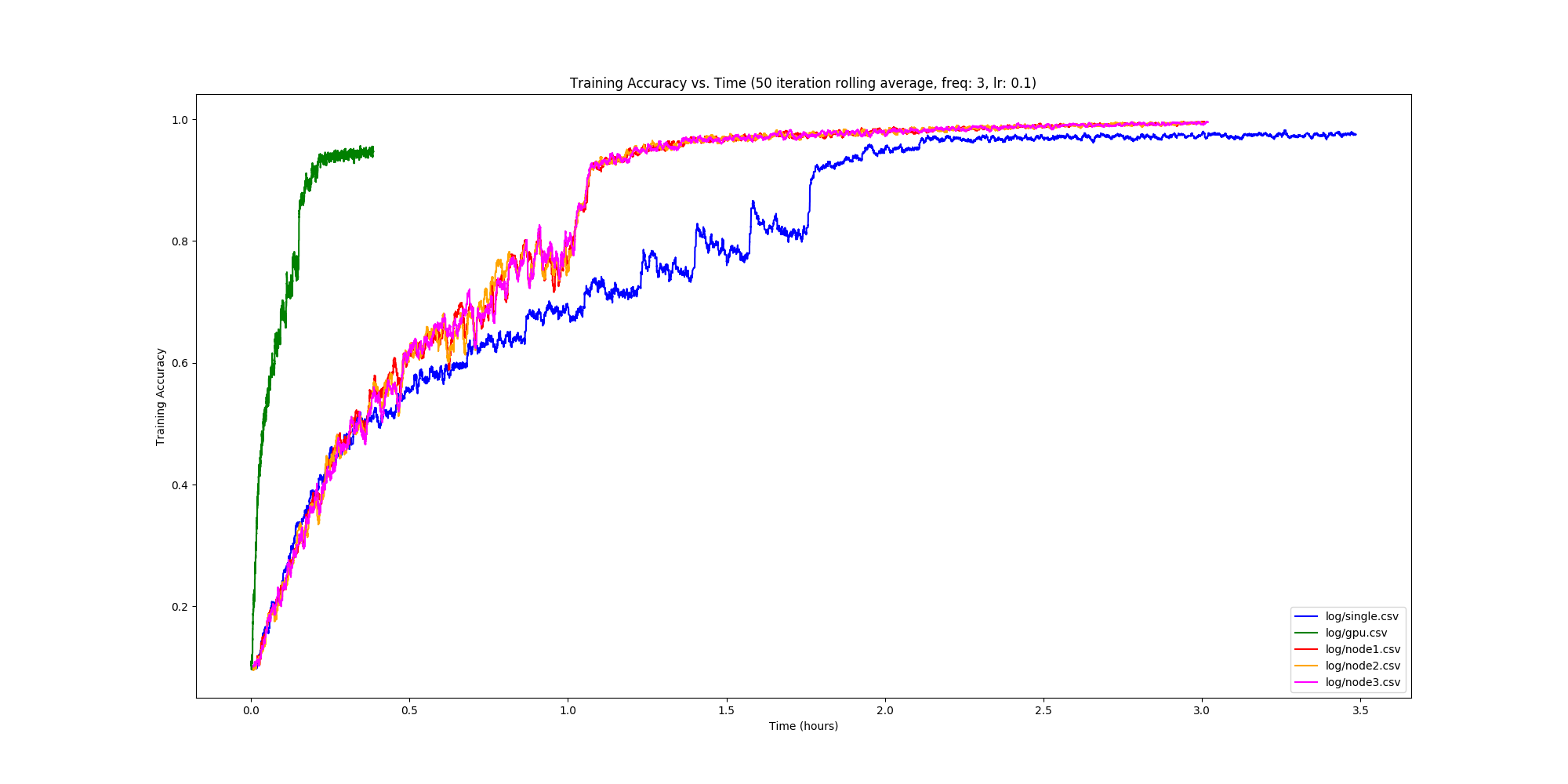
Implementing DistBelief
Over the past couple months, I’ve been working with Rohan Varma on a PyTorch implementation of DistBelief.
DistBelief is a Google paper that describes how to train models in a distributed fashion. In particular, we were interested in implementing a distributed optimization method, DownpourSGD. This is an overview of our implementation, along with some problems we faced along our way.
Please check out the code here!
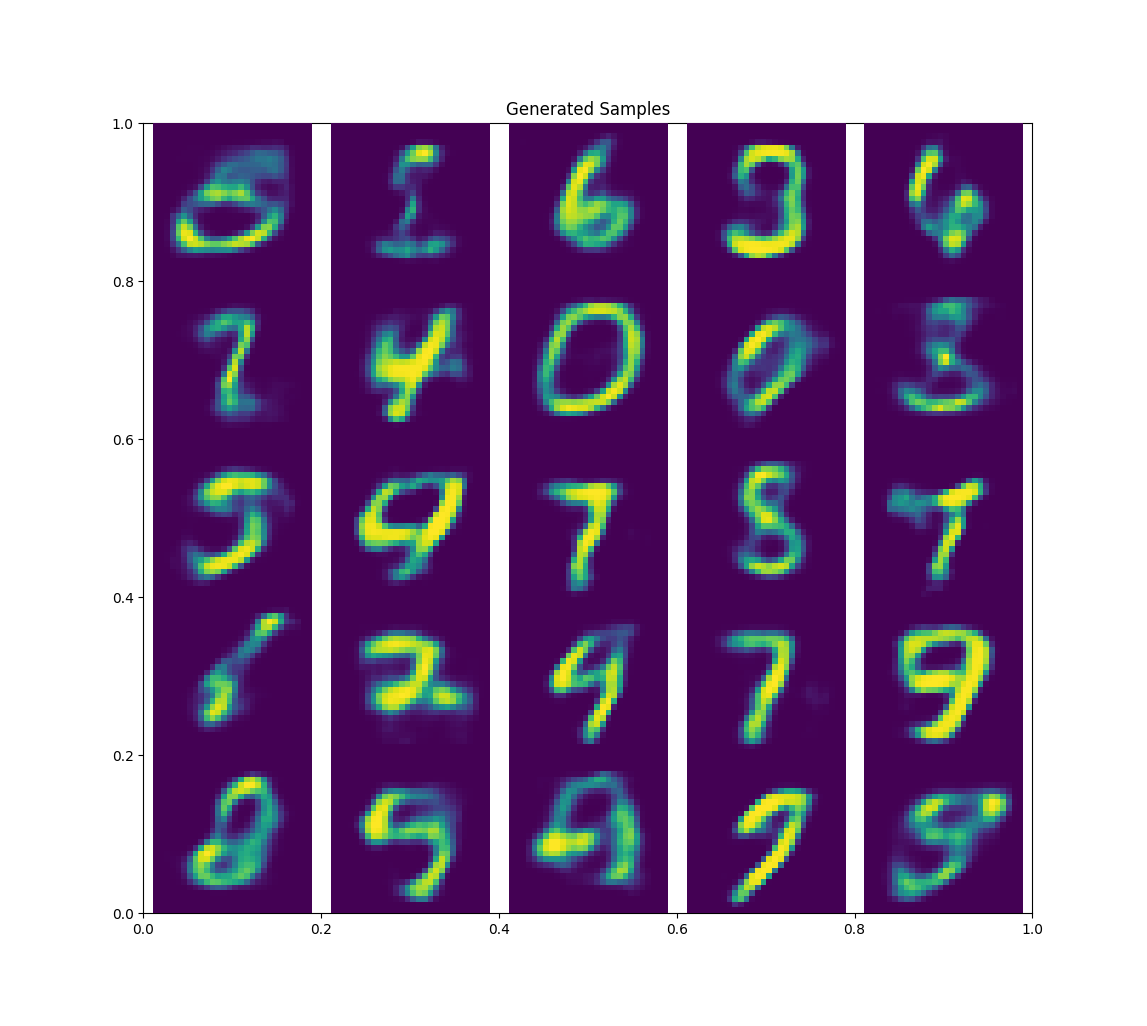
Variational Autoencoders
Next up, let’s cover variational autoencoders, a generative model that is a probabilistic twist on traditional autoencoders.
Unlike PixelCNN/RNN, we define an intractible density function
\[p_\theta(x) = \int p_\theta(z) p_\theta(x \vert z) dz\]\(z\) is a latent variable from which our trainig data is generated from. We can’t optimize this directly, so instead we derive and optimize a lower bound on the likelihood instead.
Generative Models
I’m going to be doing a series of blog posts about generative models, and how one can use them to tackle semi-supervised learning problems. In this post I’m going to go over PixelRNN/CNN, a generative model that
Generative models can be thought of a form of unusupervised learning or density estimation. We are trying to model the underlying distribution from the data.
Caching
When we write programs for computers, we often abstract away memory as a large, fast contiguous byte-addressable array. But we have a problem when we try to implement this abstraction in hardware - it turns out that it’s impossible to satisfy all these conditions.
Creating memory that is both fast and large is extremely expensive - however it’s possible to cheaply make a small amount of fast memory, and it’s also possible to make a large amount of slow memory.
To provide the illusion of a large amount of fast memory, we can construct the memory hierarchy, namely a series of caches.

Ensemble Methods
An explanation of how some popular ensemble methods work for machine learning.
Let’s say we have some simple classifier. This classifier will either make bias or variance related errors.
Using RNNs to predict user submission
This is a blog post I wrote for work about predicting whether a user would submit a Blend application or not.Logic
We can use logic, along with a Knowledge Base, which consistents a set of sentences, in order to reason and draw conclusions.
Logical reasoning is gaurenteed to be correct if the available information is correct.
Constraint Satisfaction
Constraint satisfication is similar to search problems. You can check out a solver I wrote here
For a group of variables, \(x_1, x_2, \ldots , x_n\), with domains \(D_1, D_2, \ldots , D_n\), we want to find an assignment for each variable such that no constraints are violated.

Medical Imaging Techniques
X-Rays
Oscillating current creates electromagnetic waves
Larmor Formula - \(P = \frac{2}{3}\frac{m_e r_e a^2}{c}\) The power of an electromagnetic wave is in terms of it’s radius, mass, acceleration, and the speed of light.

Constraint Satisfaction Solver
This is a post about constraint satisfaction.
If you’re interested by this blog post, you should check out my AI notes for more information about constraint satisfaction and other similar concepts.
Reasoning Under Uncertainity
We handled uncertainty before via belief states. However, when interperting partial sensor information, belief states create a huge number of states. This leads to the qualification problem.
In general, laziness, theoretical ignorance and practical ignorance keep us from deducing with pure logic. To deal with degrees of belief we will use probability theory.

Computer Systems Architecture
Measuring Performance
The instruction count, or IC, is the number of instructions that a program must execute. CPI refers to cycles per instruction, and is usually fixed for different instructions.
Graphical Models
Graphical models are a method of representing uncertatainty and reasoning. To do this generate a graph, and set probabilities for each node in the graph.
Machine Learning
Machine learning is the science of getting computers to learn to perform a task without being explicitly programmed.
A Dataset can be represented by a matex \(X\), where each column is a feature and each row is a sample. \(Y\) is a vector of labels/outputs.

CS188 Project
Literature Review
A literature review of some of the tools we used can be found here
Summary
Using a novel combination of LDA and Document Vectors, our project aims to assist doctor’s in creating reports by providing real-time suggestions of information doctors may have missed. Additionally, our robust machine learning model can be used to categorize and find similar documents.
Search
Many problems, such as 8-puzzles, n-queens, or solving a rubic’s cube can be formulated as search problems.
Formulating Search Problems
All search problems should have these parts:
Image Processing
Linear Image Transformations
Computer Graphics Notes have information about types of transformations and homogenous coordinates.
Image Interpolation
Direct interpolation lead to black spots, so instead we use indirect interpolation.

Configuring a ML Server
This is a run-down of how we set up a server for machine learning, along with information on how to connect and use the server.
Artificial Intelligence
Turing Test
The Turing Test is a test devised by Alan Turning. The test calls for a computer and a human to be put in two seprate rooms, and another human to converse with both the human and the computer. If the human observer thinks he/she is talking to another human, the computer is said to have passed the Turing test.
Winograd Schema
Winograd Schema are another series of problems that are used to test for understanding. The idea is to have a sentence, with two possible meanings and to let the computer pick two choices that make sense.
E.g. The city councilmen refused the demonstrators a permit because they [feared/advocated] violence. Who [feared/advocated] violence?

Computer Graphics
Points, Lines, Vectors, Planes
A linear combination of \(m\) vectors is given by \(\textbf{w} = a_1\textbf{v}_1 + \ldots + a_m\textbf{v}_1\)

CS188 Literature Review
Goal of the project
In the last few years, machine learning models have become increasingly powerful, and accessible. Although practically science fiction a decade ago, the frontier of computer vision is capable of labeling arbitrary images with resounding accuracy. Despite this prodigious progress, the medical field has been slow to embrace its potential for diagnosis of medical images. In our project, we hope to analyze MRI scans and their accompanying doctors notes to train a machine learning model to associate images with notes. Using a medical dictionary, our model will associate image features with specific ailments. This model would be able to accurately generate notes and diagnoses through the images.

Dockerizing Web Applications
This blog post is about the anatomy of a sample docker project you can find here. Make sure you have Docker installed - if you don’t follow the instructions here to install it.


Reduction And Intractibility
Complexity Classes
With complexity classes, we aim to determine the “difficulty” of a problem. They allow us to know what is solvable in polynomial time and what isn’t. This is what the \(P = NP\) problem deals with. \(P=NP\) implies that for any polynomial time verification solution, there is a polynomial time solver for the problem. Most computer scientists believe that \(P \neq NP\). Assuming \(P \neq NP\),

Randomness
Randomness in Algorithms
When you have many good choices, just pick one at random. Randomness can be used to speed up algorithms and ensure good expected runtime.
Linearity of Expectations
Let \(x\) and \(y\) be two random variables. Linearity of Expectations states that
\[E[x+y] = E[x] + E[y]\]That is, the expected value of the sum is the sum of the expectations.

Divide And Conquer
There are usually three steps to a divide and conquer algorithm
- Divide the problem into subproblems
- Recursively solve each subproblem
- Merge the results together
ACM AI in Review
For the past year, I have been the president of AI at UCLA, or ACM AI. Leading ACM AI has been a wonderful experience for me, and I would do it again in a heartbeat if need be. Luckily, ACM AI is now in the very capable hands of Rohan Varma and Adit Deshpande.
Leading a club is hard, and I wanted to share some of the things I learned over the past year.

Dynamic Programming
What is the idea behind dynamic programming?
Dynamic Programming breaks down problems into subproblems, then
- solves those subproblems from smallest -> largest
- uses the solution of those subproblems to solve the larger problem

Greedy Algorithms
What are Greedy Algorithms?
Greedy Algorithms work by building the general solution one step at a time. The forego thinking about the future and take the best possible step each time until they have a complete solution.

Simulated Annealing
This is a post about Simulated Annealing.
The Problem
Simulated Annealing is an optimization technique. It is a probabilistic technique to approximate the global max/min of a function. In this post, I describe how to use Simulated Annealing to solve the Traveling Salesman problem.

Acm Reading List 2017
Here's a collection of several books that we found interesting and informative!

Twitter Tensorflow Sentiment Analysis
This is a personal project that I wanted to start working on. The general idea is to train an RNN for sentiment analysis and then create a webapp to pull twitter data based on geolocation to see how different parts of the nation are feeling.

