Twitter Tensorflow Sentiment Analysis
11 Jan 2017 | machine-learning nlpThis is a personal project that I wanted to start working on. The general idea is to train an RNN for sentiment analysis and then create a webapp to pull twitter data based on geolocation to see how different parts of the nation are feeling.
The different parts are as follows:
- Creating a Machine Learning Model
- Connecting the model to a small Flask API
- Creating a frontend to display the data
Sentiment Analysis Model
I also wanted to use this as an opportunity to learn Tensorflow, so that is the framework that I’m using to write the model. Everything will be in python, and I’ll go over most of the code that I wrote. You can see the github repo here.
First off, we create an object that represents our RNN.
class TextRNN(object):
def __init__(self, input_layer_size, output_layer_size, hidden_layer_size, vocab_size, embedding_size, l2_reg=0.0):
Now we can create placeholders for our input X, output y, and also our dropoput probabilities.
self.X = tf.placeholder(tf.int32, [None, input_layer_size], name='X')
self.y = tf.placeholder(tf.float32, [None, output_layer_size], name='y')
self.droput_keep_prob = tf.placeholder(tf.float32, name="droput_keep_prob")
This lets us feed these values in later when we train the model as part of tensorflow.
I used word vectors to capture some of the semantic/syntatic relationship of the words in the tweet. You can read more about the power of word vectors here
#training word embeddings (NOTE: these will be trained along with the rest of the model, these are not preloaded)
with tf.device('/cpu:0'), tf.name_scope('embeddings'):
W = tf.Variable(tf.random_uniform([vocab_size, embedding_size], -1.0,1.0))
self.embedding = tf.nn.embedding_lookup(W, self.X)
Next we have to create the RNN by chaining together a bunch of LSTM Cells. LSTMs allow information to persist in a neural network. You can think of how as you read, you rely on the previous words to determine the meaning of the current word. That’s a very hand-wavy explanation of LSTM’s, but you can read more here
Tensorflow makes it really easy to create an RNN using a couple of their built in tools.
#creating the rnn
network = tf.nn.rnn_cell.LSTMCell(hidden_layer_size, state_is_tuple=True)
#applying droput
network = tf.nn.rnn_cell.DropoutWrapper(network, output_keep_prob=self.droput_keep_prob)
val, state = tf.nn.dynamic_rnn(network, self.embedding, dtype=tf.float32)
# we have to transpose here to get the output to the right dimensions
val = tf.transpose(val, [1,0,2])
# this gets the last output of the RNN - basically it should contain all the important words
last = tf.gather(val, int(val.get_shape()[0])-1)
Next theres a softmax layer to classify the tweet as either negative or positive
W = tf.Variable(tf.truncated_normal([hidden_layer_size, output_layer_size]), name='W')
b = tf.Variable(tf.constant(0.1, shape=[output_layer_size]), name='b')
# determine the output
with tf.name_scope('output'):
self.scores= tf.matmul(last, W) + b
self.prediction = tf.argmax(self.scores, 1)
Next we have to create a loss function to optimize. We can use the built in softmax_cross_entropy_with_logits function to do so.
It’s worthwhile to note that we feed in the unnormalized scores into this function, as it is optimized to take these in. Feeding in the result of a softmax function into this function will cause it to not perform properly
I also added a way to check the error of the model by simply seeing how many misclassifications that it makes
with tf.name_scope("loss"):
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(self.scores, self.y))
with tf.name_scope("error"):
mistakes = tf.not_equal(tf.argmax(self.y,1), tf.argmax(self.scores, 1))
self.error = tf.reduce_mean(tf.cast(mistakes, tf.float32))
That’s our model! Now we just have to train it!
Getting data and processing
I looked around for twitter sentiment data, because I felt that that would lead to the best performance on my model. I ended up finding Sentiment140, which has more than a million labeled training examples and also a test set. The training data was split into Positive, Negative, and Neutral Tweets. I only used the positive and negative examples.
Training script
After loading all the data, I created an instance of our RNN class and also an Adam optimizer.
rnn = TextRNN(x_train.shape[1], y_train.shape[1], 75, len(vocab_processor.vocabulary_), 200, l2_reg=0.0)
optimizer = tf.train.AdamOptimizer(0.001)
minimizer = optimizer.minimize(rnn.loss)
Now I could initialize my tensorflow session with
init_op = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init_op)
saver = tf.train.Saver()
With my session initialized, I can train my model simply by running
status, loss = sess.run([minimizer, rnn.loss],
{
rnn.X: inp,
rnn.y: out,
rnn.droput_keep_prob: 0.5
})
I ended up trainig on a batch size of 1000 for ~200 epochs, which mean that in the end my code ended up looking something more like this:
#run for all epochs
for i in range(epoch):
# Determine test error (also append to a list)
test_error = sess.run(rnn.error,
{
rnn.X: x_test,
rnn.y: y_test,
rnn.droput_keep_prob: 1.0
})
errors.append(float(test_error))
ptr=0
bar = tqdm(total=no_of_batches)
for j in range(no_of_batches):
inp, out = x_train[ptr:ptr+batch_size], y_train[ptr:ptr+batch_size]
status, loss = sess.run([minimizer, rnn.loss],
{
rnn.X: inp,
rnn.y: out,
rnn.droput_keep_prob: 0.5
})
ptr += batch_size
bar.set_description("Iteration: " + str(j) + " | Loss: " + str(loss) + " | Error: " + str(test_error))
bar.update()
losses.append(float(loss))
Evaluating the model and tuning hyperparamaters
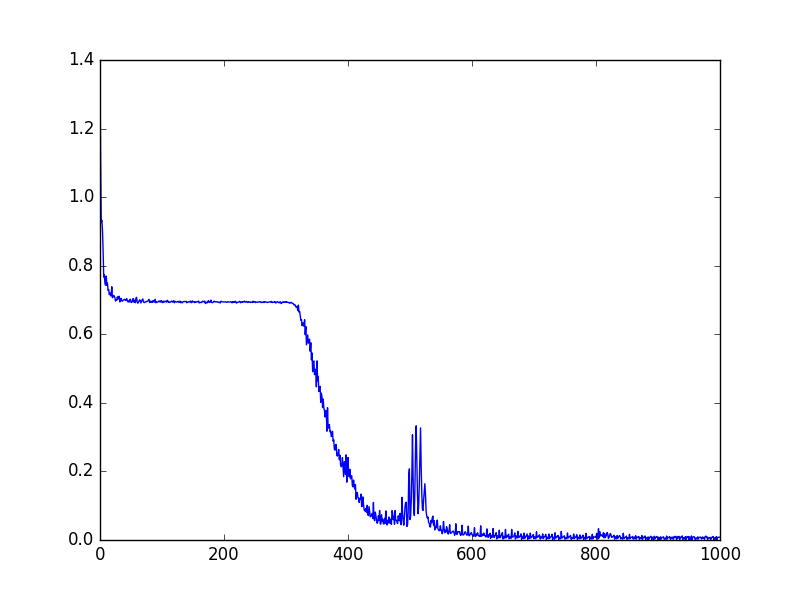
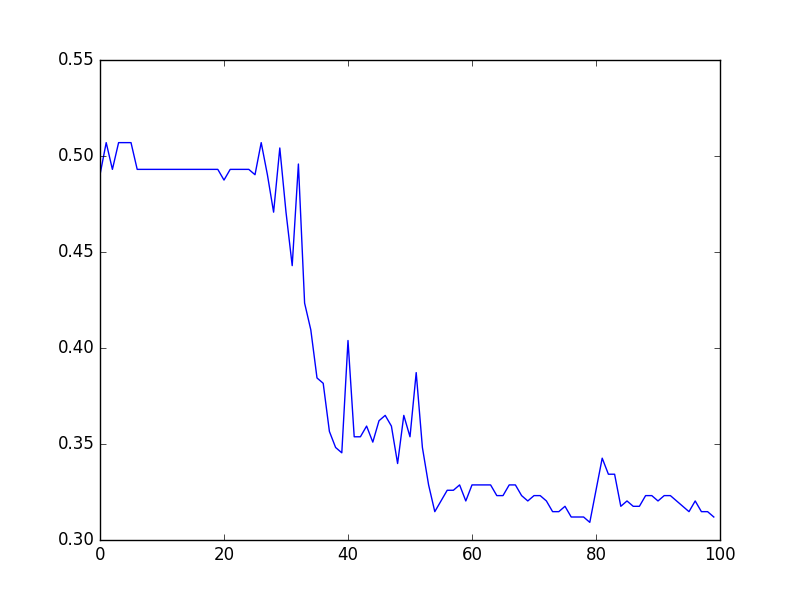
With just a bit of tuning, I set the learning rate to 0.001, the hidden layer size of the LSTM to 75, and the dimension of the word embedding to 100. Dropout keep % was at 50%. I was pretty impatient so I only ended training on 10000 training examples with a batch size of 1000 for 100 epochs. I ended with a 68-69% test accuracy. I’ve included some graphs of the loss function and test error over time. Please excuse the unlabeled graphs
Loss Function vs. Iterations
Test Error vs. Epochs
Takeaway
I eneded up being very pleased with the end result. This took about a week to do, and I think if I had access to a GPU or even a more powerful computer (I’m runnning on a dual core laptop) I could get a much better test error with just a bit more tweaking.
Overall I would say that this was a success! You can check out the full code here Thanks for reading this, and stay tuned for the next part!